ARIMA时间序列模型水质预测应用
ARIMA 时间序列模型简介
时间序列是研究数据随时间变化而变化的一种算法,是一种预测性分析算法。它的基本出发点就是事物发展都有连续性,按照它本身固有的规律进行。ARIMA(p,d,q)模型全称为差分自回归移动平均模型 (Autoregressive Integrated Moving Average Model,简记 ARIMA). 是比较成熟且简单的时间预测模型之一。其中 AR 为自回归, I 为差分, MA 为移动平均。
趋势参数:
- p:趋势自回归阶数。
- d:趋势差分阶数。
- q:趋势移动平均阶数。
差分
差分(difference)又名差分函数或差分运算,差分的结果反映了离散量之间的一种变化,是研究离散数学的一种工具。它将原函数f(x) 映射到f(x+a)-f(x+b) 。差分运算,相应于微分运算,是微积分中重要的一个概念。总而言之,差分对应离散,微分对应连续。差分又分为前向差分、向后差分及中心差分三种。
通常情况下我们用到的是前向差分公式如下:
xk=x0+kh,(k=0,1,…,n)
△f(xk)=f(xk+1)−f(xk)
差分的阶
称为阶的差分,即前向阶差分 ,如果数学运用根据数学归纳法,有其中,为二项式系数。特别的,有前向差分有时候也称作数列的二项式变换
在高锰酸盐指数序列预测可行性的说明
通过观察水质变化趋势,高锰酸盐指数波动不剧烈,存在明显的中心波动规律。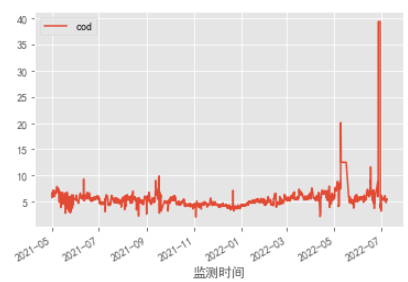
python实现
环境准备
1 | |
连接数据
通过数据库,excel 都可以,列名为监测时间、设备名称、设备因子、监测值。
1 | |
数据处理
1 | |
主要是 将数据生成无空连续的逐小时 时间序列数据 插值方法为线性插值
数据解读
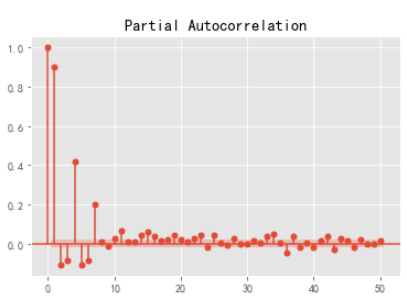
查看acf
1 | |
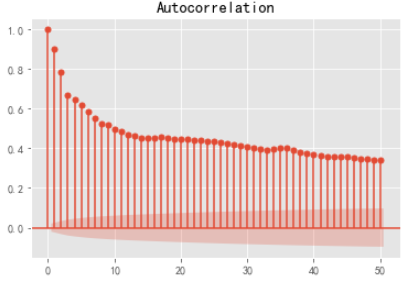
解读 拖尾为p 。基本大于0.5 现在和未来有很强的相关性
单位根检验
1 | |
原始序列的ADF检验结果为: (-7.19465930048855, 2.452407467867345e-10, 37, 9199, {‘1%’: -3.431061069214289, ‘5%’: -2.8618542472812902, ‘10%’: -2.5669372687639176}, 11281.50483165621)
解读:P值小于显著性水平α(0.05),不接受原假设(非平稳序列),说明原始序列是平稳序列。
白噪声检验
1 | |
一阶差分序列的白噪声检验结果为: lb_stat lb_pvalue 1 7467.631465 0.0
p值为0小于0.05,不是白噪声
综上可以采用 arima 模型
定阶 人工识图
1 | |
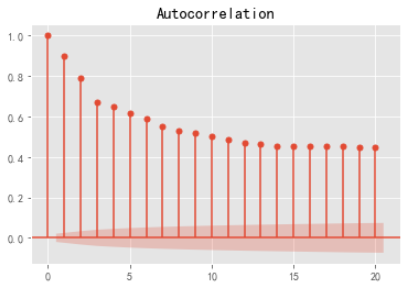
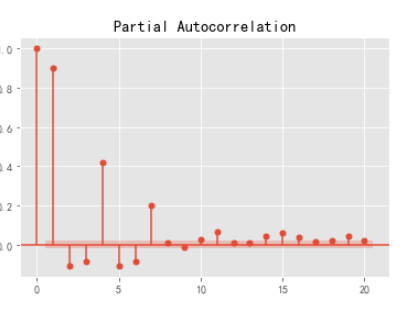
参数调优
AIC调优
1 | |
也可以用BIC调优 不再赘述
模型建立
1 | |
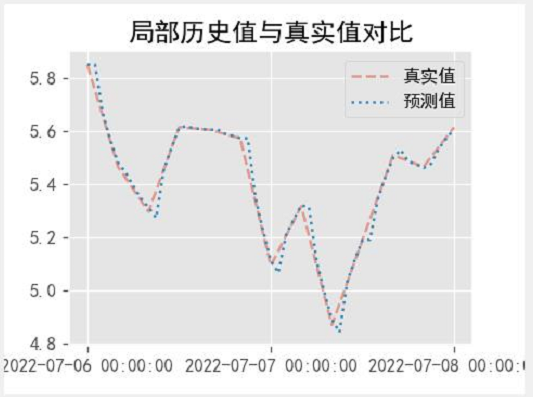
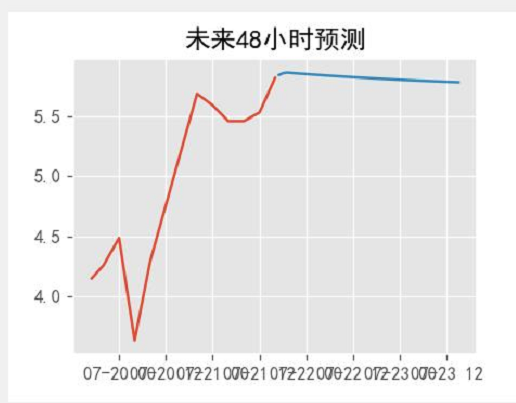
模型预测
定义画图函数
1 | |
1 | |
1 | |
模型可视化及GUI初探
用Tkinter 实现自动选择站点及因子
1 | |
结果预览
模型评价
模型评价方法: 浓度准确率, 等级准确率
浓度准确率

等级准确率:实测的类别与预测的类别相同时,则视为预测正确,预测正确的个数占预测的总个数的百分比,即为模型预测准确率。指标预测准确率的详细计算方法如下式:
Pi为类别相对误差,T 为验证期内实测值的时间点数,t为实测值与预测值对应的时刻,pit为实测的类别与模拟的类别相比值,如果类别相同则为1,否则为0。
结果提取
1 | |
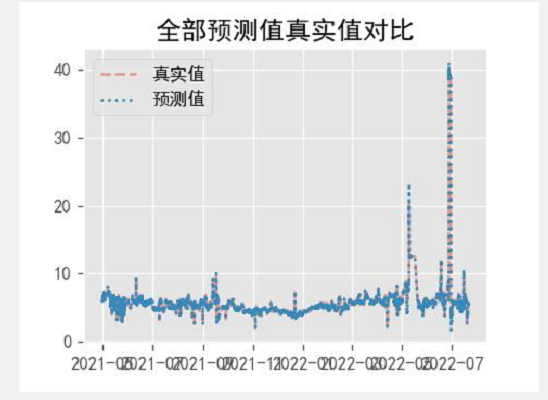
结果分析
时间原因用的excel 分析
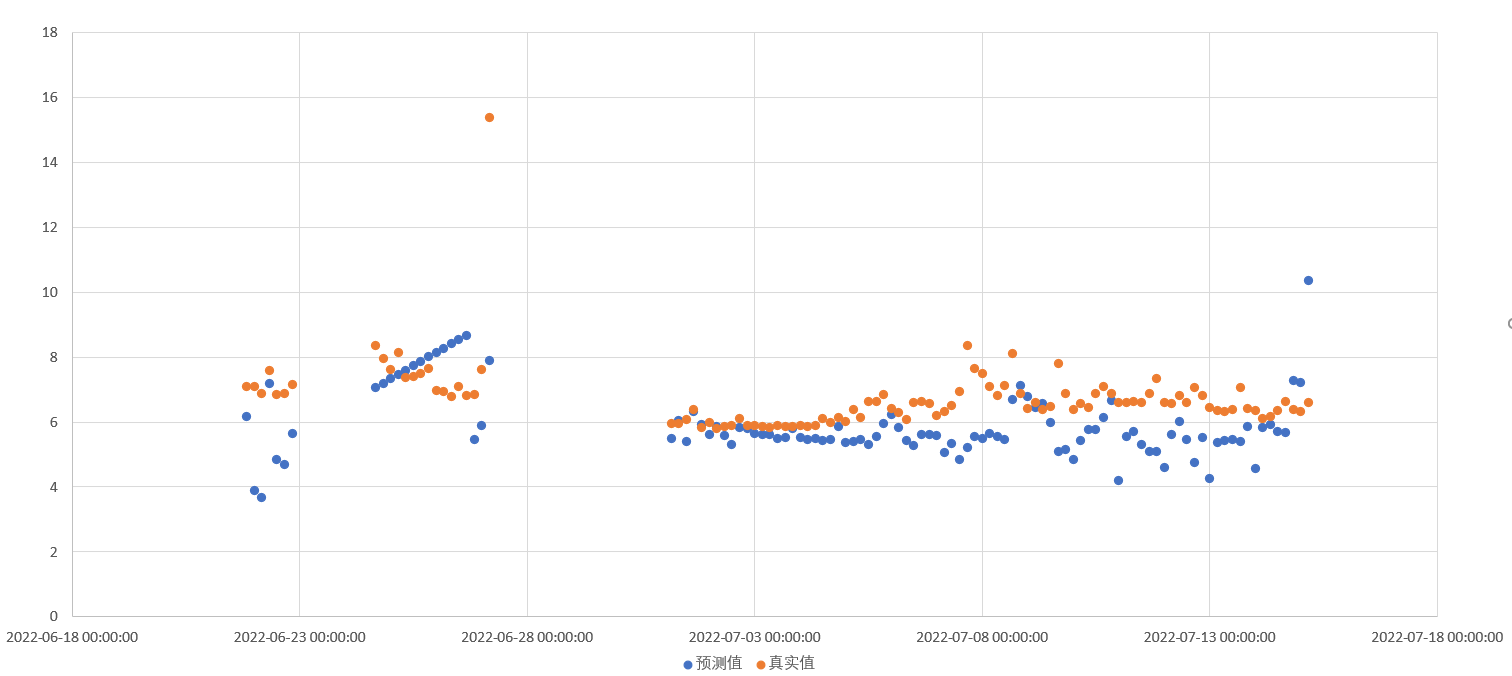
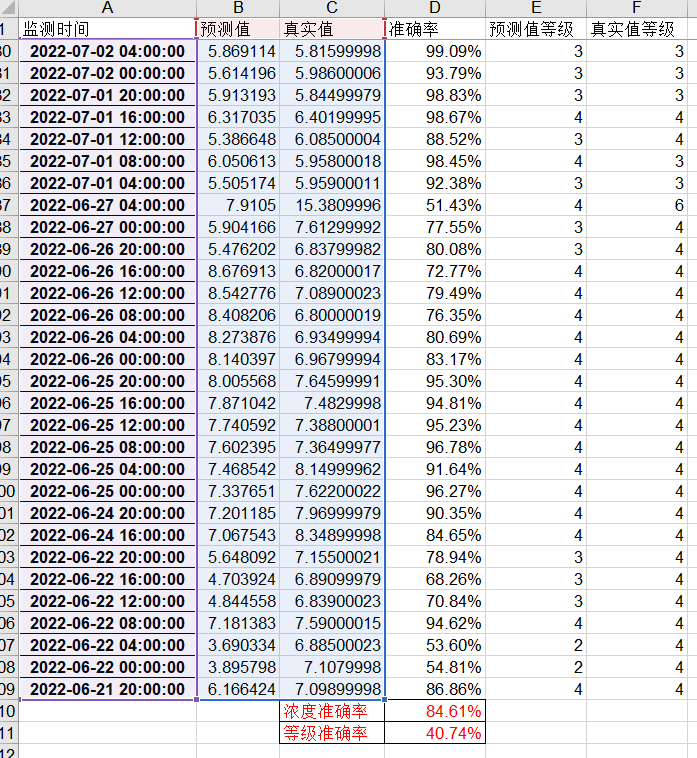
对比了6月21日~2022/7/15 高指真实值与预测值的结果,浓度预测准确率为84.61%,等级准确率40.74%,等级准确率偏低的原因为实际监测结果在6附近波动,为Ⅲ类水质标准。
预测对比时间窗口存在降雨,实际结果有一定波动,浓度预测准确率能到达84.6%,有一定的推广价值。
ARIMA .summary() 解读
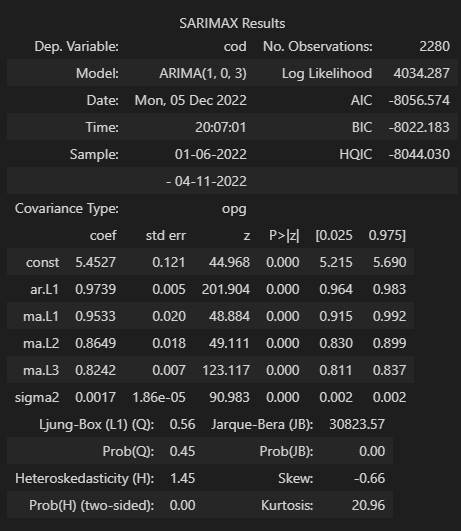
- 左上 为模型基本信息,Dep. Variable(需要预测的变量)、Model(模型及其参数)、Date、Time、Sample(样本数据)、No. Observations(观测数据的数量)
- 右上 Log Likelihood(对数似然函数)标识最适合采样数据的分布。虽然它很有用,但AIC和BIC会惩罚模型的复杂性,这有助于使我们的ARIMA模型变得简洁。赤池的信息准则(AIC)有助于确定线性回归模型的强度。AIC 会惩罚添加参数的模型,因为添加更多参数将始终增加最大似然值。贝叶斯信息准则(BIC)与 AIC 一样,BIC 也会惩罚模型的复杂性,但它也包含数据中的行数。Hannan-Quinn信息标准(HQIC),与AIC和BIC一样是模型选择的另一个标准;但是它在实践中并不常用。AIC 、BIC 越小越好
- 中部 确保模型中的每个项在统计意义上是否显著。若p值大于0.05,则项不显著。
- 下部:Ljung-Box(modified Box-Pierce test)测试错误是白噪音 Ljung-Box (L1) (Q) 为Lag1的LBQ检验统计量,其Prob(Q)为 0.01,p值为0.94。由于p值高于0.05,因此我们不能拒绝零假设(误差是白噪音)
讨论与总结
- ARIMA 模型在高锰酸盐指数上的预测效果超过80%,经过初步研究,适用于水质在线站点。
- 模型可用于单站点单因子预测,不需要其他参数,约束小,预测精度高。
- 模型对波动剧烈的因子,预测效果不好,不适用于所有因子,所有站点。
- 对于新的数据集需要做平稳性检验,白噪声检验。
- 需要采用数据人工识图+自动的方式实现定阶,选择最优的 p,d,q。
- 可以继续在 ARIMAX(多元时间序列模型)等方面深入研究。